
The initial era of technical curiosity has passed. Today, when I speak with UK solicitors, barristers, and inquiry teams, the dialogue is no longer about the "potential" of the technology—it is about operational reliability, data sovereignty, and legal defensibility. From the boardrooms of the City to specialized chambers, the same fundamental concerns continue to surface:
The Capability Gap
"Can Relativity aiR truly navigate the 'dirty data'—handwritten logs and poor-quality scans—that frequently define the UK Public Inquiry landscape?"
The Judicial Standard
"If we rely on GenAI for disclosure, how do we justify that specific methodology before a Judge or an Inquiry Chair?"
The Sovereignty Question
"Is our sensitive data remaining within the UK sovereign border, or is it being processed in a global 'black box'?"
Is Relativity the strategic choice, or are Reveal, DISCO, and Everlaw delivering features better suited to the nuances of the UK market?
Relativity aiR for Review has undeniably dominated the industry headlines. After establishing its presence in the high-stakes world of US litigation, it is now seeking to redefine the UK market. However, my months of dedicated research and technical deep-dives suggest a much more nuanced reality than the marketing brochures suggest.
The goal of this analysis is to look past the hype. I want to share genuine peer insights and provide an honest comparison of how aiR actually performs within the UK legal framework. Let’s begin by examining exactly how this tool integrates into a professional review workflow.
Operational Mechanics: Where Relativity aiR Fits
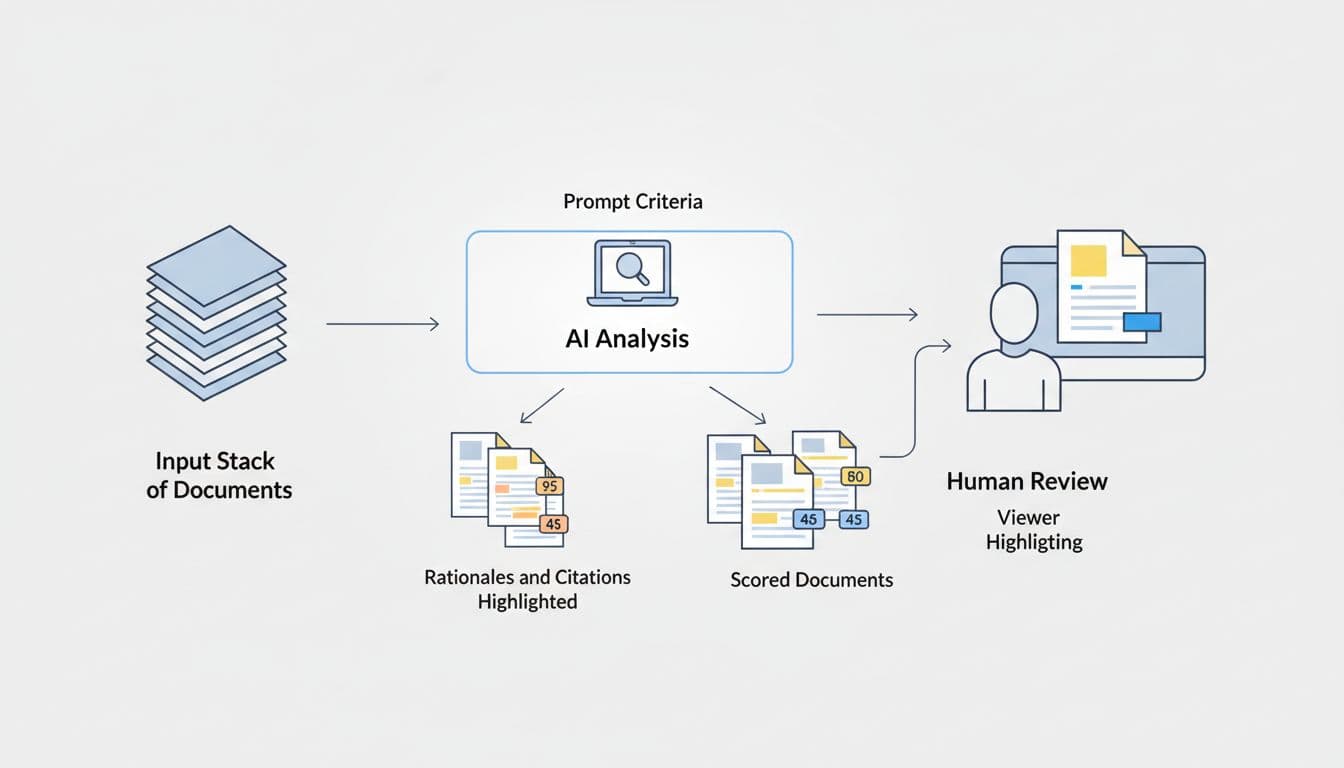
At its core, Relativity aiR acts as a sophisticated first-pass reviewer that analyzes extracted text against your specific prompt criteria. These criteria define relevance, identify "hot" documents, and categorize issues with a level of speed traditional methods cannot match.
The Mechanics of Relativity aiR: Integration and Workflow
At its core, Relativity aiR acts as a sophisticated first-pass reviewer that analyzes extracted text against your specific prompt criteria. These criteria define relevance, identify "hot" documents, and categorize issues with a level of speed traditional methods cannot match.
Relativity aiR for Review has certainly grabbed the headlines. After cementing its popularity in the high-stakes world of US litigation, the platform is now looking to transform the UK market. But my months of dedicated research, technical deep-dives, and candid discussions with peers suggest a more nuanced reality.
The goal of this blog is to look past the marketing. I want to share genuine industry insights, provide my own detailed findings, and give you an honest comparison of how aiR fits into the broader legal tech landscape. Let’s start by looking at what Relativity aiR actually does and where it fits in a modern review workflow.
What Relativity aiR actually does, and where it fits in a review workflow
At its simplest, Relativity aiR acts like a first-pass reviewer that reads extracted text against instructions you write. Those instructions are called prompt criteria, and they tell the system what counts as relevant, what looks like a key or "hot" document, and which issue categories matter.
This setup is significant because it changes where the tool fits. aiR is not a total replacement for legal judgment. It sits near the front of the workflow, helping teams sort, explain, and prioritize material before deeper human review, QC, and final production decisions are made.
However, my months of dedicated research, technical deep-dives, and candid discussions with UK legal teams suggest a more nuanced reality: a palpable sense of skepticism remains. The real questions that need answering before fully relying on this technology—especially in the high-stakes context of UK public inquiries and sensitive matters—are still very much on the table. Is Relativity aiR actually safe and defensible enough for disclosure work? What do peers who have used it under the pressure of tight deadlines and high risks really say? And, crucially, how does it stack up against leading AI tools from other providers like Reveal, DISCO, Nebula, Everlaw, and OpenText?
The goal of this blog is to look past the marketing. I want to share genuine industry insights from peers, provide my own detailed findings from months of investigation, and give you an honest comparison of how aiR fits into the broader legal tech landscape. Let’s start by looking at what Relativity aiR actually does and where it fits in a modern review workflow.
What Relativity aiR actually does, and where it fits in a review workflow
At its simplest, Relativity aiR acts like a first-pass reviewer that reads extracted text against instructions you write. Those instructions are called prompt criteria, and they tell the system what counts as relevant, what looks like a key or "hot" document, and which issue categories matter. Instead of learning from coded examples in the way older TAR workflows often do, aiR reviews each document on its own against your criteria and returns a recommendation.
This setup is significant because it changes where the tool fits. aiR is not a total replacement for legal judgment. It sits near the front of the workflow, helping teams sort, explain, and prioritize material before deeper human review, QC, and final production decisions are made.
The core features that make aiR different from older review tools
The main difference is the prompt-based approach. You provide aiR with a case summary, relevance rules, and issue definitions, and it applies those rules document by document. For each item, it can return a prediction, a score, a written rationale, and a short section of "self-critique" called considerations, which flags what might make the prediction wrong.
Critically, it also shows citations from the document itself. This makes the output easier to challenge and much easier to defend. In the Viewer, those cited passages can be highlighted inline, allowing a reviewer to jump straight to the text behind the recommendation rather than simply taking the system’s word for it.
Beyond relevance, aiR can support several common review tasks:
- First-pass review, by separating likely relevant from likely non-relevant material.
- Key document review, by spotting documents that may be especially important.
- Issue analysis, by classifying documents against selected issue categories.
- Document summaries and topics, by generating short descriptions of each document.
The scoring is also practical. Documents are ranked from junk through to very relevant, while errored items sit apart with a score of -1. That helps teams filter quickly, export result sets, and build saved views for triage. If needed, selected documents can move into Review Center for human review.
Two features stand out for workflow control. First, Prompt Kickstarter can draft initial criteria from case papers such as review protocols or requests for production. Second, prompt criteria validation lets teams compare aiR predictions with human coding on a sample set, using measures such as precision and recall. That gives you a way to test whether the setup is good enough before wider use. It can also surface conflicts between AI predictions and reviewer decisions, which is often where the real learning starts.
Why the tool can speed up large disclosure exercises
In large disclosure work, speed comes from getting useful structure early. aiR can do that by reading huge sets of text and pushing likely relevant, borderline and key material to the top. As a result, case teams get earlier insight into facts, themes and problem documents instead of waiting for a long manual review to take shape.
That has a few direct benefits. You can prioritise the right custodians and date ranges sooner. You can reduce the burden on reviewers by sending them the documents most worth their time. You also get a more even first-pass analysis, because the same prompt criteria apply across the set.
Published material also points to high throughput, with averages often in the tens of thousands of documents per hour and, depending on data and system load, up to millions per day. For big investigations or public inquiry work, that can shift the timetable in a meaningful way.
Faster review is only useful if the team still checks what matters.
That is why aiR works best as supervised acceleration, not unattended automation. Its output can guide QC, highlight disagreements with human coding, and give senior reviewers a clearer route into the difficult documents first.
The limits users need to understand before relying on results
The biggest limit is simple. aiR only sees extracted text. It does not understand a document the way a person does when meaning depends on layout, embedded images, video, handwriting, formula logic in spreadsheets, or visual context. If the text extraction is poor, the analysis will be poor too.
That matters in UK matters because inquiry and disclosure datasets often include scanned PDFs, handwritten notes, image-heavy records and mixed file types. A human may spot meaning from a stamp, annotation or attachment relationship that aiR cannot see from text alone. The same applies where relevance depends on an attachment rather than the message body.
There are other practical limits as well:
- Highly structured files, such as spreadsheets and some forms, are more likely to trigger citation problems
- Document and prompt size limits apply, so very large inputs may need a different handling plan
- Non-English use is supported by the underlying model, but testing has been much stronger on English-language material
Relativity also notes that outputs can vary slightly between runs, and citations can occasionally be flagged as possibly ungrounded. For that reason, the safest approach is to treat aiR as a strong review aid with human oversight, not as a final decision-maker.
What users say about Relativity aiR, the good, the bad, and the practical reality
Market feedback on Relativity aiR is promising, but it needs context. Direct, public aiR-only reviews are still fairly limited, so the clearest picture comes from a mix of early user commentary, wider Relativity sentiment, and Relativity's own published claims. Taken together, the message is fairly consistent: teams see real upside, but they also see work, cost control, and process discipline behind the good results.
Where users see real value in live matters
The strongest praise centres on speed with structure. Users like that aiR does not just sort documents quickly, it also gives a recommendation with citations and rationale. That makes the output easier to test, easier to challenge, and far easier to trust than a plain score from a black box.

In live matters, that matters a great deal. Review teams often need to know why a document was pushed up the queue. aiR's cited passages can help a senior lawyer or review manager check the machine's thinking without starting from scratch.
Positive themes come up repeatedly:
- Teams value faster first-pass review, especially when deadlines are tight.
- Large matters benefit from early case insight, because likely hot or relevant material surfaces sooner.
- Users also like the Relativity ecosystem, since aiR sits alongside workflows they already use.
- Many see value in consistency, because one set of prompt criteria can be applied across a very large population.
Published claims and market commentary point to major gains in some matters, including review time reductions of up to 85%, very large document volumes processed in days rather than weeks, and substantial savings in lawyer hours. Those figures are useful, but they should be read as reported examples, not a promise. Outcomes depend on data quality, prompt quality, matter complexity, and how much human checking the team still needs.
Another point comes through clearly. Users tend to like aiR most when they use it as a triage engine, not as a final judge. It can help identify what deserves human attention first, which is often where the commercial and strategic value sits.
The practical benefit is finding the right documents sooner, with traceable reasoning
The common complaints that come up again and again
The biggest complaint is simple: Relativity is not the lightest platform to learn, and aiR adds a new layer to that. Teams need to understand prompt drafting, testing, validation, result review, and when to re-run criteria. If your instructions are vague, rushed, or incomplete, the output can be weak.
That is a real shift for review teams used to older workflows. aiR asks users to think more like they are writing a review protocol for a very literal junior reviewer. Leave out an acronym, code name, or key factual distinction, and the system may miss what you meant.
Common criticisms usually fall into five areas:
- Learning curve: strong users adapt quickly, but newer teams can struggle at first.
- Pricing opacity: billing and document-based charging have not always felt simple, even though core aiR tools are now included in standard RelativityOne.
- Performance on huge matters: aiR is built for scale, yet some users still report occasional slowness when jobs are very large or queues are busy.
- Support concerns: sentiment is mixed, with some firms happy and others wanting faster or clearer help.
- Platform complexity: some teams still find Relativity heavier than newer cloud-first rivals.
There is also a more basic truth here. aiR is not plug-and-play for every team. Good results usually come from iteration. Relativity's own workflow guidance leans on a three-part approach: develop prompt criteria on a sample, validate against human coding, then apply at scale. That tells you something important. The product works best when users treat setup as part of the review job, not a one-off admin task.
In practice, this means weak prompts can waste both time and money. A poor first run may still teach you something useful, but it is still a paid run, and documents are billed each time they go through analysis. For some teams, that makes prompt discipline just as important as the AI itself.
What these reviews mean for UK law firms, chambers, and inquiry teams
For UK buyers, the pattern is fairly clear. If your team already runs RelativityOne, has capable admins, and follows a defined review process, aiR is easier to absorb. You already have the platform habits, the permissions model, the saved searches, and the review controls. That reduces friction and helps you get to useful testing faster.
Smaller firms, specialist chambers support teams, and lean investigations groups may see things differently. If they do not have in-house Relativity depth, a lighter tool may feel easier to adopt. That does not mean aiR is the wrong fit. It means the setup burden is more noticeable, and the benefits may take longer to show.
For public inquiries and other high-scrutiny matters, user feedback points to a broader lesson. Governance often matters as much as raw AI power. Inquiry teams usually care about traceability, repeatable workflows, reviewer management, and the ability to explain decisions later. aiR's rationale, citation checking, and validation workflow fit that need better than tools that only return a score.
A simple way to read the market feedback is this:
- Established Relativity teams are more likely to unlock value quickly.
- Smaller or less technical teams may prefer simpler products, even if they give up some control.
- Inquiry and disclosure-heavy matters should judge aiR on auditability and workflow fit, not speed alone.
So, the practical reality is not that aiR wins every comparison. It is that it tends to make the most sense where the team can support it properly, validate it carefully, and use its explainability as part of a defensible review process.
Is Relativity aiR safe to use in UK litigation and public inquiries?
The short answer is yes, often, but only if you define safety properly. In this context, safety is not just cyber security. It also means data protection, legal defensibility, accuracy controls, auditability, and day-to-day governance.
For UK litigation and public inquiries, that wider view matters. A tool can sit in a secure cloud and still create risk if the team cannot explain how it was used, where data went, or why the output was trusted. Relativity aiR gives you some strong building blocks here, but it still needs careful setup and supervision.
Security, data handling, and what the platform says about model training
Relativity says aiR for Review runs inside RelativityOne and uses Azure OpenAI for the language model layer. The review flow is document by document, not batch learning from your matter. In other words, the system sends one document for analysis, gets a result back, and then moves to the next.
That point matters because aiR is not described as learning from prior documents in your project. It applies the prompt criteria and its existing model knowledge to each item separately. Relativity also says submitted customer data sent for processing is not retained beyond the customer instance for training other AI models, whether from Relativity, Microsoft, or another third party.

That is a useful assurance for legal teams handling witness evidence, privileged material, or inquiry records. It reduces one of the first fears people raise, which is, "Will our documents end up training someone else's model?" Based on the platform materials, the answer given by the provider is no.
Around that AI layer, the wider RelativityOne environment is positioned as an enterprise-grade platform with the sort of controls buyers expect in serious legal work. The supplied context also points to GDPR, ISO 27001 and SOC 2 Type II aligned credentials in the wider environment, which will matter to procurement, risk and infosec teams.
Just as important, the up-to-date context supplied here did not surface major UK-specific aiR security incidents or breaches tied to litigation or public inquiries. That is helpful, but it is not the same as a legal guarantee. A clean search result is reassuring, not decisive.
A secure platform is only one part of a safe review process. Your own settings, contracts and data flows still carry the real risk.
So, before any live matter, organisations should still check their hosting region, processor terms, access controls, retention settings, export controls, and logging. Safety starts with the vendor, but it ends with your implementation.
GDPR, data geography, and the UK public sector risk questions
For UK users, the harder questions usually sit under GDPR and public law risk, not just technical security. If you're reviewing personal data, special category data, or confidential state material, you need a clear lawful basis and a defensible processor setup. You also need confidence on confidentiality, audit trails and who can see what.
Relativity's materials help on part of that picture. The platform is framed as a processor environment, and the wider context points to the use of standard transfer safeguards where cross-border transfers arise. That said, one line in the documentation deserves close attention: for some AI technology, customer data may be processed outside the designated geographic region.
That does not automatically make aiR unsuitable. However, it does mean UK legal teams should not assume that choosing a preferred region answers every residency question. For routine commercial disputes, that may be acceptable once the legal and technical review is complete. For public inquiries, government work, regulated sectors, or nationally sensitive investigations, it needs a much closer look.
A few practical questions should be answered before rollout:
- Where is the main RelativityOne instance hosted?
- Where does AI processing actually occur for the features you plan to use?
- What transfer mechanism applies if processing leaves the expected geography?
- Does your confidentiality regime permit that movement?
- Can you evidence all of this later if challenged?
There is another clue in the product design. Relativity notes that document summaries are opt-in only in certain European instances, including France, Germany, Ireland and the Netherlands, because of processing location considerations. That tells you data geography is not a side issue. It is an active operational constraint.
For UK public sector teams, that matters a lot. If your case includes Cabinet-level material, police records, health data, or inquiry evidence with strict handling rules, then region and transfer analysis should happen before anyone runs a test set. In practice, the right question is not "Is aiR GDPR compliant in the abstract?" It is "Does this exact deployment fit this exact matter?"
Defensibility in court or inquiry, why human validation still matters
Even if the security and GDPR answers look sound, there is still the courtroom question. Can you defend the workflow if the other side, the court, or an inquiry chair asks how documents were identified and checked?
This is where aiR is on stronger ground than many generic AI tools. Relativity's workflow follows a develop, validate, apply model. First, you draft and refine prompt criteria on a small sample. Next, you validate the results against human coding. Only then do you apply the approach more widely.
That mirrors how sensible legal review works anyway. You test the protocol, check disagreements, tighten the definitions, and only then scale it up. The process is less like pressing a magic button and more like training a junior reviewer with written instructions, then checking their work before giving them the full archive.
Validation is a real strength here. Through Review Center, teams can compare aiR predictions against human coding and look at measures such as precision, recall, elusion and error rate. For UK disclosure and inquiry work, that is not just a nice extra. It goes to defensibility.

If you ever need to explain your methodology, these controls help. You can show:
- What instructions were given.
- How those instructions were tested.
- Where AI and humans agreed or conflicted.
- What changes were made before wider use.
That is far better than saying a black-box tool produced a ranking and the team accepted it. aiR also stores predictions separately from human coding fields, which helps preserve a cleaner audit trail during testing.
Still, none of this removes the need for legal judgement. AI output should support review decisions, not replace them. The tool only analyses extracted text, so it may miss context a human reviewer would catch from layout, attachments, imagery, or poor OCR. Inquiries often contain exactly that kind of awkward material.
A sensible UK answer, safe enough if the controls are right
So, is Relativity aiR safe to use in UK litigation and public inquiries? Safe enough, in many cases, if the controls are right. That means a clear review protocol, tested prompt criteria, human supervision, and a proper data protection review before live use.
It's a better fit when the team already has sound review governance. If you can define relevance clearly, run a sample set, validate against human decisions, and document the method, aiR can be a sensible and defensible review aid. That is especially true for large text-heavy matters where speed and explainability both matter.
Caution rises in a few familiar situations:
- The data includes highly sensitive government or security-related content.
- The matter has strict residency or sovereign hosting demands.
- The collection is image-heavy, poorly extracted, or full of structured files.
- The team lacks strong QC, prompt drafting, or review governance.
- Decision-makers want AI to replace judgement, rather than support it.
In those cases, aiR may still help, but the scope may need to be narrower. For example, it might be used for triage, issue spotting, or limited validation support rather than broad first-pass review.
The practical UK answer, then, is not a blanket yes or no. It is closer to this: aiR can be used safely where the matter, deployment and governance all line up. If they don't, the risk sits less in the model itself and more in how the team chose to use it.
Relativity aiR versus Everlaw, Reveal, DISCO, Nebula, OpenText and other leading tools
If you're comparing review platforms, the smartest question isn't which vendor shouts loudest about AI. It's which tool fits your matter, your team, and your risk profile. For UK disputes, investigations and inquiries, buying criteria usually come back to the same things: defensibility, ease of use, cost clarity, hosting options, and whether the AI shows its working.
That is where Relativity aiR becomes easier to place. It is not the easiest platform in the market, and it is not always the cheapest. However, it often looks strongest when matters are large, messy and heavily supervised.
Where Relativity aiR stands out against the field
Relativity aiR has a clear edge in enterprise-grade review workflow. If your team already works in RelativityOne, aiR fits into a mature environment with saved searches, permissions, Viewer controls, Review Center queues, reflected result fields, and versioned prompt criteria. That matters because AI rarely works well in isolation. It works better when it sits inside a review process that people already trust.

Another strength is how aiR handles prompt-based document analysis with reasons attached. It does not simply score documents and leave you guessing. Instead, it can return a prediction, a rationale, a cautionary counterpoint, and supporting citations from the document text. Relativity also says it checks citations and flags possible grounding problems, which gives review teams something concrete to inspect rather than a black-box answer.
For complex matters, that is a real advantage. You can test the output, challenge it, and compare it to human coding before scaling up. The built-in develop, validate, apply model also helps here. Teams can refine prompt criteria on a smaller sample, compare aiR predictions against reviewers in Review Center, and look at measures such as precision and recall before wider use. That sort of validation is not just nice to have in UK litigation or inquiry work. It is often the difference between a tool that looks clever and a workflow that stands up later.
Relativity also tends to suit large, document-heavy disputes. Published platform guidance points to very high throughput and job controls built for serious volume. Add in issue analysis, key document review, summaries, and broad workspace-level controls, and you have a tool that feels built for matters where the data mountain is steep and every path needs audit trails.
The result is fairly simple. If a case already lives in RelativityOne, aiR often makes the most sense when you need:
- strong review controls
- AI output with citations
- validation against human coding
- support for large populations
- a workflow that can stretch from triage to
That combination makes aiR especially attractive for major disclosure exercises, internal investigations, and public-facing inquiries where process discipline matters as much as review speed.
Where Everlaw, Reveal, DISCO and OpenText may be a better fit
Relativity is not the default winner for everyone. In fact, several competitors may be a better fit if your team values speed to adoption, lighter admin work, or simpler commercial planning over deeper platform control.
Everlaw often stands out on usability. Its reputation is strong for a clean interface, faster onboarding, and a more collaborative feel. Public comparison data also points to high user satisfaction, which matters more than many buyers admit. If your review team wants to get productive quickly, or if you don't have much in-house platform support, Everlaw will look attractive. Its Everlaw AI Assistant features are also easier to engage with because they feel close to the user, providing guidance and insights without being buried in system logic.
Reveal sits in a different spot. It tends to appeal to teams that want broad workflow coverage with a more guided experience than Relativity. That can work well when you want modern cloud delivery and a platform that helps move users through the job without as much setup complexity. A key consideration is how explainability and support for very large matters align with specific project needs and expectations. Making full use of its AI capabilities, including Reveal Ask and Aji (not yet available in the UK), may also involve establishing clear, defensible review workflows, including validating and overseeing how prebuilt models are applied in practice.
DISCO usually enters the conversation when buyers want a cloud-first platform with simpler pricing and less infrastructure friction. That can be a serious advantage. Legal teams do not just buy features, they buy predictability. If you want to avoid a platform that feels heavy to administer, DISCO may feel more comfortable. It is often seen as strong for fast review and intelligent search, supported by Cecilia AI tools that assist with automated document categorization and Q&A, even if buyers handling bet-the-company disputes may still want to test how far it stretches in the most complex matters.
OpenText deserves a slightly different lens. It may not dominate legal AI chatter in the same way, but it remains relevant because of its deployment flexibility and wider information governance strength. If your organisation cares deeply about where data sits, how systems connect, and whether cloud-only is acceptable, OpenText can have a strong practical case. Hybrid and on-premise options can matter a great deal for regulated sectors, public bodies, and sensitive UK work. Its eDiscovery Aviator features also provide AI-assisted review and analytics, helping teams prioritize relevant documents and gain insights earlier in the workflow.
Nebula takes a cloud-native approach focused on AI-assisted review and analytics. It can help teams accelerate document prioritization and surface insights early, while providing guidance for building defensible workflows. Its intuitive interface and integrated AI tools aim to support collaboration without requiring heavy in-house infrastructure.
A side-by-side view helps highlight the differences and make trade-offs easier to assess.
| Platform | Best fit | Main advantage | Main caution |
|---|---|---|---|
| Relativity aiR | Large, complex, high-control matters | Deep workflow, citations, validation, enterprise scale | Steeper learning curve, less simple pricing |
| Everlaw | Teams wanting ease and quick adoption | Strong usability, collaboration, high user satisfaction | Cloud-first model may not suit every data policy |
| Reveal | Buyers wanting broad workflow with guidance | Modern feel, guided experience, broad coverage | Structured experience may influence flexibility for custom workflows |
| DISCO | Teams wanting convenience and cost clarity | Cloud-first setup, simpler pricing, fast review tools | May offer less depth for the hardest matters |
| OpenText | Organisations with strict governance or hosting needs | Flexible deployment, broad governance strengths | Can feel more enterprise-heavy and less review-centric |
| Nebula | Teams seeking AI-assisted review with early insights | Cloud-native, intuitive interface, integrated AI tools for prioritization | Newer platform, may require workflow adjustments to maximize AI capabilities |
For UK teams, those differences often matter more than headline AI claims. A platform can have impressive model features and still be the wrong buy if onboarding drags, costs are hard to forecast, or your hosting options do not fit internal policy. In other words, the best tool is usually the one that matches your review pressure points, not the one with the flashiest product page.
What to say about Nebula and lesser discussed platforms without overclaiming
Nebula and some smaller platforms deserve a careful mention, but not a fictional one. Public comparison detail is thinner, and there are fewer broad market signals to lean on. That does not mean these tools are weak. It means buyers should ask harder questions before they trust the sales pitch.
For UK work, keep the checklist simple. Ask about hosting location, AI auditability, prompt or model controls, validation workflow, export quality, and real evidence on legal datasets. If a vendor cannot answer those points clearly, the problem is not the lack of buzz. It's the lack of proof.
Sparse public detail may guide further questions and evidence gathering
A buyer's scorecard for UK litigation and inquiry work
The safest way to compare these tools is not to crown a single winner. It is to score them against the work you actually do. A disclosure-heavy High Court dispute, an FCA investigation, and a public inquiry may all land on different answers.
This scorecard gives you a practical way to judge them.
| Criterion | What to look for | Tools that often look strong |
|---|---|---|
| Defensibility | Validation, audit trails, preserved prompts, comparison to human coding | Relativity aiR, OpenText, Reveal, Nebula |
| Security posture | Enterprise controls, access management, processor clarity | Relativity aiR, OpenText, Everlaw |
| Data residency options | UK or regional hosting detail, transfer clarity, non-cloud options where needed | OpenText, Relativity aiR (case-specific checks needed) |
| Ease of onboarding | Clean interface, low admin burden, quick reviewer adoption | Everlaw, DISCO, Reveal, Nebula |
| Cost predictability | Clear billing model, fewer hidden rerun costs, simpler commercial structure | DISCO, Everlaw |
| Review speed | Fast ingestion, responsive review, practical throughput at scale | Everlaw, Relativity aiR, DISCO, Reveal, Nebula |
| Multilingual support | Sensible handling of non-English data, prompt flexibility, citation readability | Relativity aiR, Reveal, Nebula |
| Mixed document handling | Performance across emails, loose files, scans, spreadsheets and forms | OpenText, Reveal, Nebula (all require testing on awkward data) |
| AI transparency | Citations, reasons, visible logic, reviewer challenge path | Relativity aiR, Everlaw, Reveal, Nebula |
A few buying patterns become clear once you look across this kind of comparison grid.
If defensibility and review control top the list, Relativity aiR remains a strong choice. Its citation-based analysis, versioned prompt criteria, and validation workflows suit legal teams that need to explain their decisions later, which is particularly useful for public inquiries and major disclosure exercises.
If ease of use and adoption is the priority, Everlaw often stands out. It meets teams where they are, rather than requiring them to become platform specialists first. For smaller UK matters, this can save more time than a feature-rich platform would.
If structured guidance and AI-assisted workflows matter, Reveal offers a compelling option. Users can combine Reveal Ask with prebuilt AI workflows to accelerate review and maintain defensible processes. It works well for UK corporate investigations, mid-to-large commercial disputes, or matters needing guided review and traceable reasoning.
If AI-assisted prioritization and early insights are important, Nebula can help teams surface key documents quickly while supporting defensible review. It is often cited by users as useful for internal investigations, compliance work, and mid-sized litigation in the UK.
If commercial clarity is the main concern, DISCO may feel more comfortable. If hosting flexibility and information governance dominate the conversation, OpenText may rise higher on your shortlist than many legal teams first expect.
The key point is simple. AI claims should sit near the bottom of your first-pass buying checklist, not the top. For UK litigation and inquiry work, the more practical question is: can your team explain the output, control the data, train reviewers quickly, and manage costs once the matter becomes complex? That is where real tool choice happens.
Final Verdict & Recommendations
Relativity aiR remains a strong option for UK litigation and public inquiries when the case brief is well-defined, the dataset is largely text-based, and teams need AI outputs that are fully explainable. User experience shows tangible improvements in review speed and earlier case insight, while the platform’s main strength continues to be process control—it provides citations, reasoning, and a validation pathway rather than asking teams to rely solely on predictive scores.
However, aiR is not automatically the right fit for every matter. Its advantages are maximized within an existing RelativityOne environment, where teams can craft prompt criteria, test them on known-coded documents, and compare results against human review before expanding. Meanwhile, Everlaw may be preferable for teams seeking rapid onboarding and a highly intuitive interface. DISCO can be appealing where cost transparency and simple pricing are priorities. OpenText may lead for organizations with complex deployment or governance requirements, and Reveal or Nebula could be better choices for teams that value guided workflows, AI-assisted prioritization, and lighter platform overhead.
For UK buyers, the practical guidance is clear: AI should supplement, not replace, careful legal judgement. aiR works best when controls are in place, data handling is verified, and the team dedicates time to validating outputs. It is less suitable where data residency requirements are strict, source text quality is uneven, or teams lack the discipline to test and monitor AI-assisted review.
The recommended next step is hands-on and evidence-driven. Run a representative sample set, use human-coded documents for comparison, iterate on prompt configurations, verify where data is processed, and track metrics such as precision, recall, conflicts, and error rates. Only after these steps should you consider a full rollout.
If aiR’s outputs consistently meet expectations in these trials, it can confidently serve as the backbone of defensible review workflows, while other platforms like Everlaw, DISCO, OpenText, Reveal, or Nebula may complement or provide alternative approaches depending on the matter’s size, complexity, and workflow preferences.
Hold up against your reviewers on your own documents, it deserves a place on the shortlist. If they do not, the better choice is the tool your team can explain, supervise, and defend when the matter gets hard.








